05-2 html+js+css是如何解析渲染的
CSS 是如何工作的 - 按照js是否存在/引入方式不同
1/3、html + css 文件的渲染流程分析
先看下面的一个示例代码
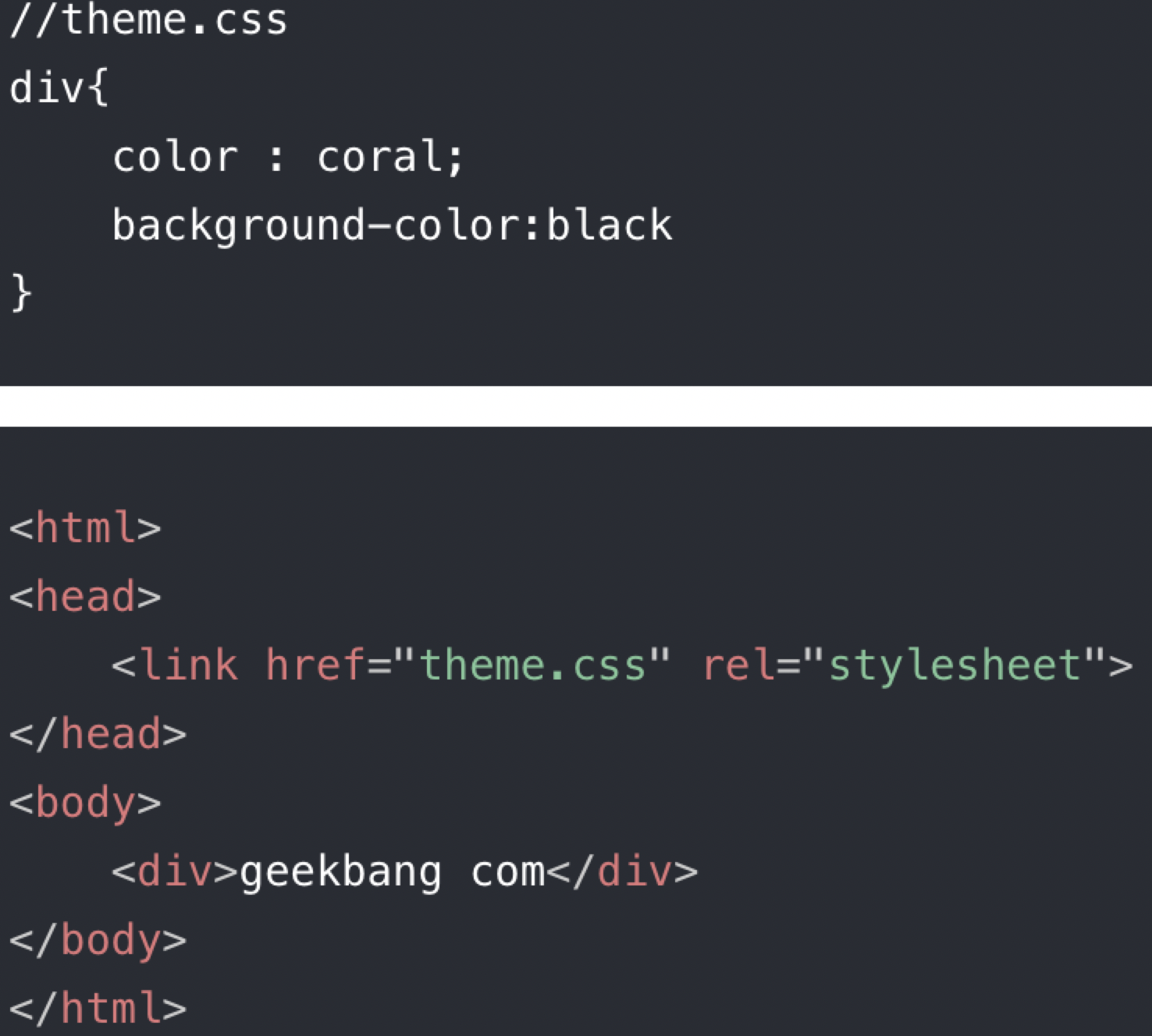
分析一下这段示例代码是怎么渲染的:
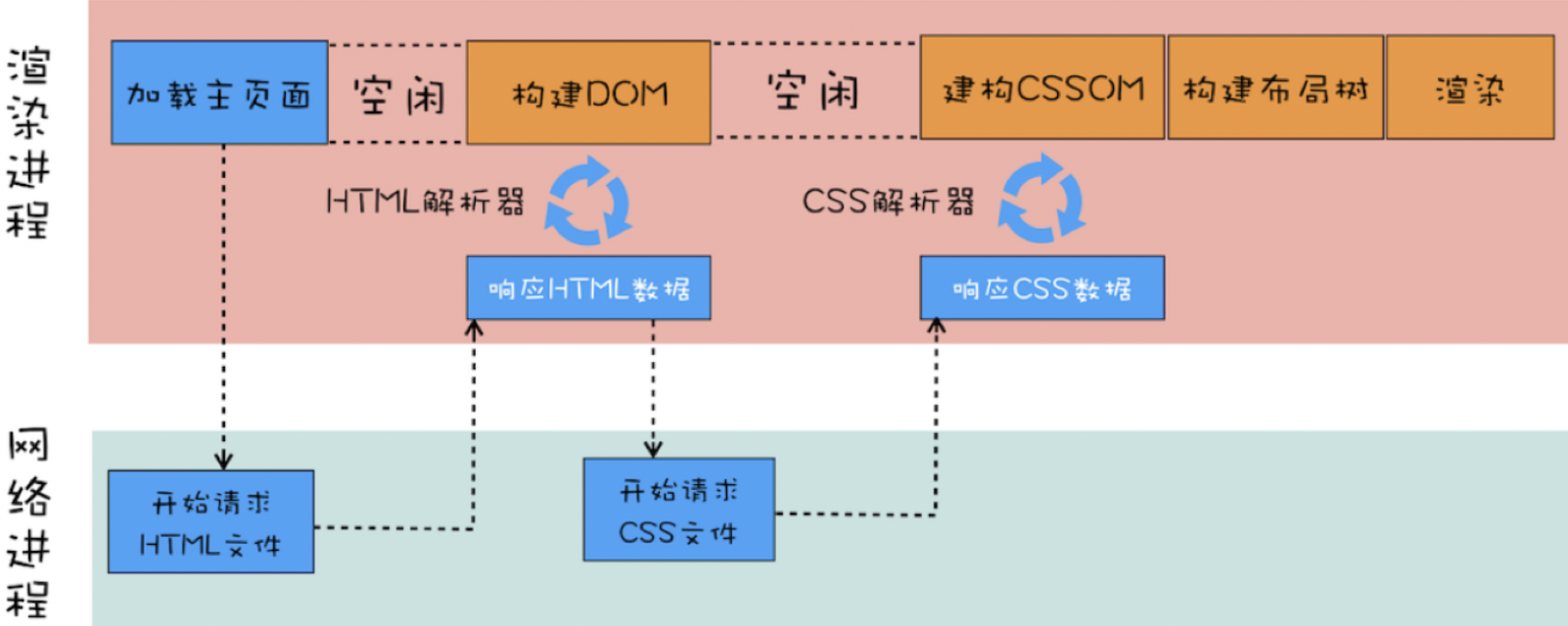
核心要注意的几点:
1、渲染进程/浏览器进程,发起的主页面请求被送到 网络进程 中去执行
2、网络进程请求到 HTML 数据后,将其发送给 渲染进程,然后渲染进程会解析 HTML 并构建 DOM,注意请求 HTML 数据和构建 DOM 中间有一段【空闲时间】
3、当渲染进程接收 HTML 文件字节流时,会先开启一个预解析线程,如果遇到 JS 文件或者 CSS 文件,那么预解析线程会 提前下载 这些数据
4、在 DOM 构建结束之后、css 文件还未下载完成 的这段时间内,渲染流水线无事可做 – 【空闲时间】,因为下一步要合成布局树,需要 CSSOM 和 DOM,所以需要等 CSS 下载完毕并解析成 CSSOM
5、等 DOM 和 CSSOM 都构建好之后,渲染引擎就会 构造布局树 – 布局树的结构基本上就是复制 DOM 树的结构,不同之处在于 DOM 树中那些 不需要显示的元素会被过滤掉,如 display:none 属性的元素、head 标签、script 标签等
6、复制好基本的布局树结构之后,渲染引擎会为对应的 DOM 元素选择对应的样式信息,这个过程就是 样式计算。样式计算完成之后,渲染引擎还需要计算布局树中每个元素对应的几何位置,这个过程就是 计算布局。通过样式计算和计算布局就完成了最终布局树的构建。再之后,就该进行后续的绘制操作了。
2/3、html + css + script 的渲染流程分析
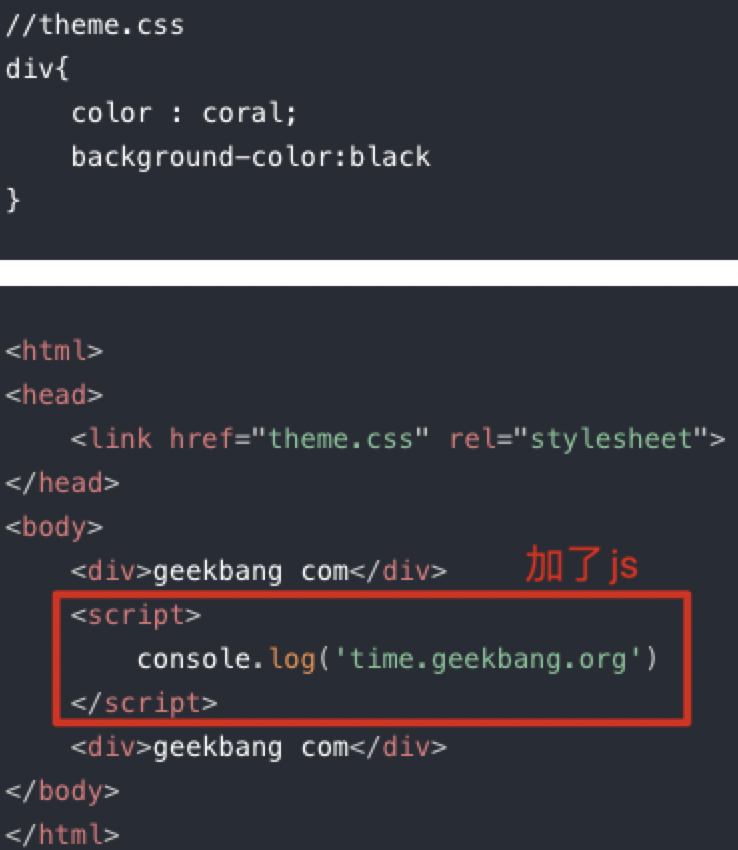
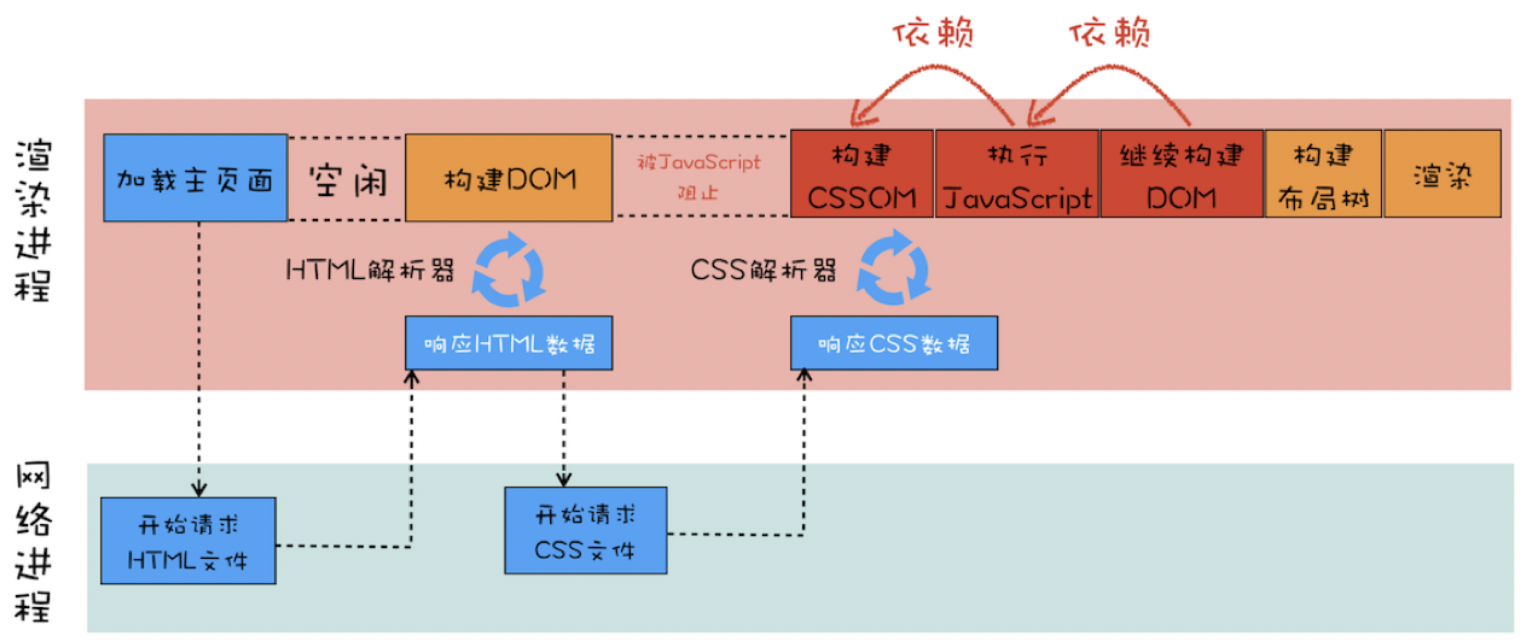
注意点:
1、解析 DOM 的过程中,如果遇到了 JS 脚本,那么需要先 暂停 DOM 解析去执行 JS,因为 JS 有可能会修改当前状态下的 DOM
2、但是在执行 JS 脚本之前,如果页面中包含了 外部 CSS 文件的引用/style标签 内置了 css 内容 – 渲染引擎需要先将这些内容转换为 CSSOM,因为 JS 有修改 css 的能力 —> 所以我们常说:css 在部分情况下也会阻塞 DOM 的生成
3/3、html + css + 引入js文件 的渲染流程分析
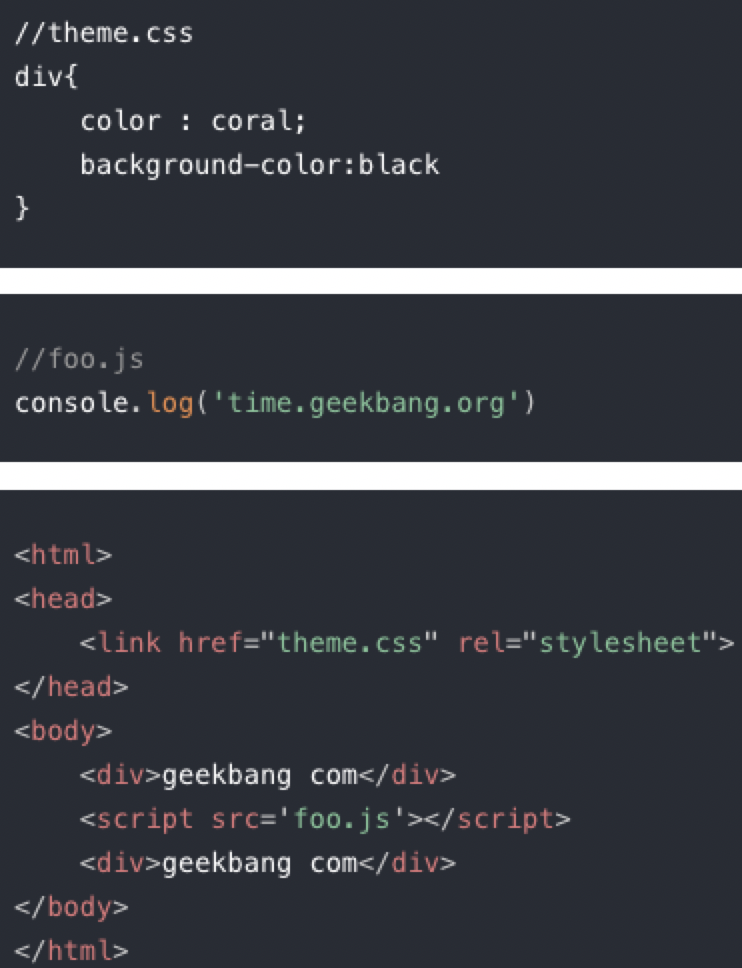
注意点:
1、HTML 预解析器识别出来了有 CSS 文件和 JS 文件需要下载,然后就同时发起这两个文件的下载请求,需要注意的是,这两个文件的下载过程是重叠的,所以下载时间按照最久的那个文件来算
2、不管 CSS 文件和 JS 文件谁先到达,都要 等到 CSS 文件下载完成并生成 CSSOM,然后再执行 JavaScript 脚本,最后再继续构建 DOM,构建布局树,绘制页面